The goal in the Capscii challenge was to solve 50 captchas consecutively in less than 100 seconds and prove that we are not human. The captcha was not your usual recognition of text though, it consisted of an operation (addition, subtraction or multiplication) on two numbers. Only problem, the numbers were printed as ASCII art on the page!

challenge screenshot
Solving the challenge using pattern matching
After an unsuccessful trial at screenshotting the element and OCRing it with Tesseract, our team turned to parsing the text, splitting the blocks of characters and matching them against a template of each digit and signs. After some fine tuning of cookies management, the 50 requests went through and we got the sweet flag!
import requests
from BeautifulSoup import BeautifulSoup
import re
def compute(lines):
count = len(lines[0])/5
numbers = [0]*count
for i in range(count):
numbers[i] = [0]*5
for j in range(5):
numbers[i][j] = lines[j][i*5:i*5+3]
signs = {
"#### ## ## ####":'0',
"## # # # ###":'1',
"### ##### ###":'2',
"### #### ####":'3',
"# ## #### # #":'4',
"#### ### ####":'5',
"#### #### ####":'6',
"### # # # #":'7',
"#### ##### ####":'8',
"#### #### ####":'9',
" ### ":'-',
" # ":'*',
" # ### # ":'+'}
calc = ""
for num in numbers:
calc = calc + signs[num[0]+num[1]+num[2]+num[3]+num[4]]
return eval(calc)
def parse(content):
html = BeautifulSoup(content)
divs = html.findAll('div', attrs={'style': 'font-size: 7pt;font-family: monospace; white-space: pre; line-height: 6pt;'})
return [ re.sub(r'[A-Z]', '#', divs[0].contents[i]) for i in [0,2,4,6,8] ]
url = "http://capscii.insomni.hack/start"
response = requests.get(url)
cookies = response.cookies
for i in range(51):
values = parse(response.content)
solution = compute(values)
response = requests.post(url, data={'sol': solution}, cookies=cookies)
cookies = response.cookies
print response.content
Solving the challenge using OCR
As we were on-site with two teams we can also present the OCR solution that the other team used to solve the challenge. Using the gocr program allowed us to easily train the character recognition and build a database of learned characters . We initially tried to build the database directly on the presented challenges but were far away from reaching the required 50 correct results after a few training sessions. Initially tesseract-ocr was used, but the accuracy level prior to blocking chars (next step) was too low, and the challenge reset the score every time the script would submit an answer. So, to improve the consistency of the shown digits we decided to replace all uppercase characters in the presented challenge with the ■ character, resulting in a simple font that could easily be recognized using OCR.

challenge with replaced characters
gocr can be trained on the command line with a simple command such as “gocr -C “0-9–*+” -l 250 -m 150 -a 100 ./image.png -o ./output.txt”. Whenever gocr recognizes a distinct pattern it will prompt the user to map the pattern to a character. In the example gocr has recognized the pattern for the character 2 and shows it on the command line together with the adjacent characters.
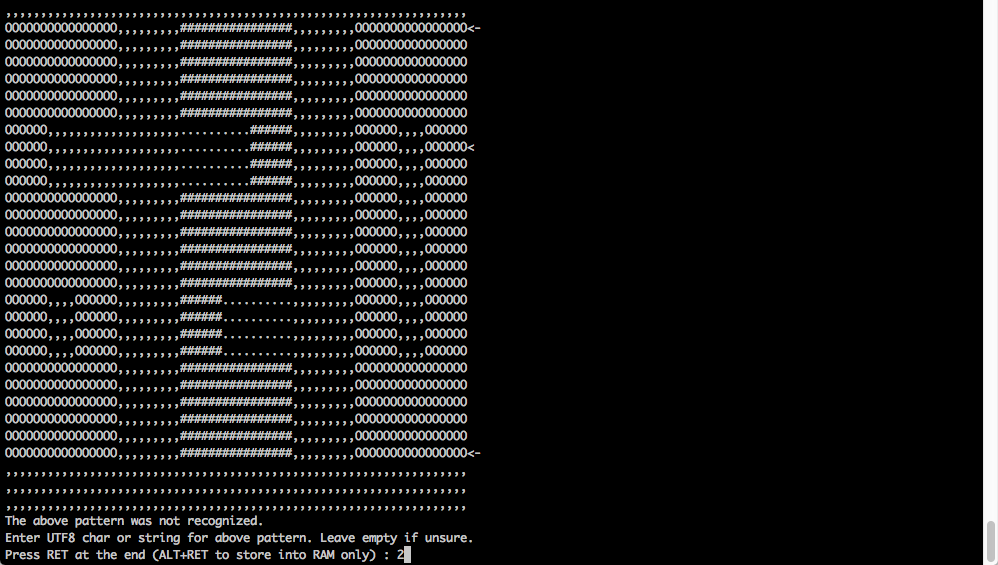
After an initial round of training (again in gocr) that took a few seconds only, we got the complete database of characters required.
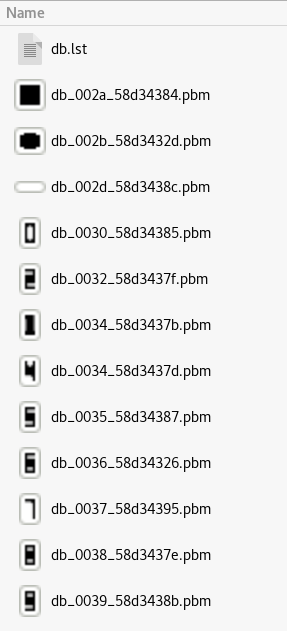
database of learned characters
Combining all steps in a simple bash script:
#!/bin/bash
curl -c jar -s http://capscii.insomni.hack/start > calcme-temp.html
for i in `seq 1 50`;
do
# take the downloaded file, replace uppercase chars with visual blocks, squash layout, writeout
cat ./calcme-temp.html | sed 's/[A-Z]/\■/g' | sed 's/6pt/3pt/g' > ./calcme.html
# grab the interesting bits of the view, make it an image
wkhtmltoimage --crop-x 0 --crop-y 51 --crop-w 245 --crop-h 31 ./calcme.html ./calcme-full.png
# set certainty level of gocr before querying user
gocr -C "0-9--*+" -l 250 -m 150 -a 100 ./calcme-full.png -o output.txt
# do the calc, save results
cat output.txt | bc > results.txt
# submit
curl -b jar -c jar -X POST -s -d "sol=`cat results.txt`" http://capscii.insomni.hack/start > calcme-temp.html
done
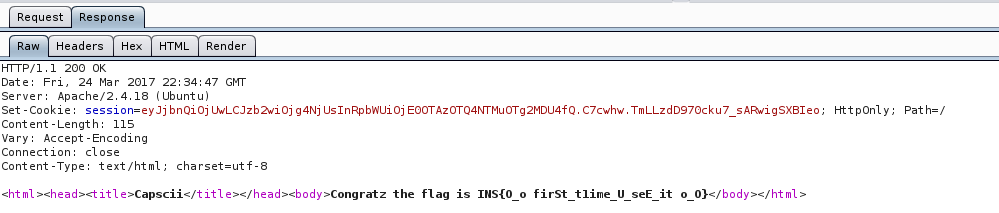
After successfully solving 50 challenges in a row we were presented with the flag:
Leave a Reply