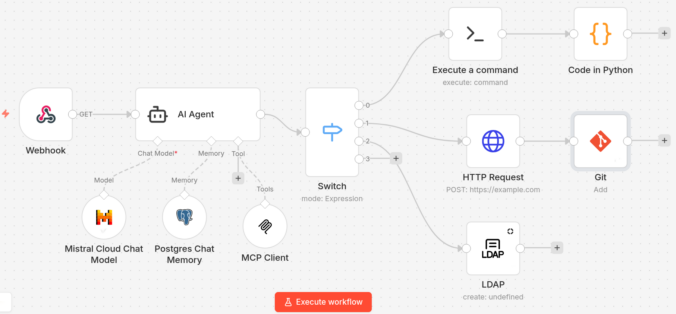
Automation platforms such as n8n are often introduced as productivity tools: connect a few systems, automate repetitive work, maybe add some AI. Inside a corporate network, however, that framing is incomplete. A self-hosted workflow engine can reach internal systems, execute actions on behalf of users, and hold sensitive credentials. That puts it in the same […]
Compass Security Blog
Offensive Defense
In this second part, we demonstrate how a Cyber Resilience Act (CRA) assessment is performed in practice. Using a low-cost IP camera as an example, we show how a product is classified, how threats are modelled, how hardware and firmware are analysed, and how compliance gaps against IEC 62443-4-2 can be identified. You may want […]

The Cyber Resilience Act (CRA) is a regulation introduced by the European Union to strengthen cybersecurity requirements for products with digital elements.In simple terms, the CRA sets mandatory cybersecurity rules for hardware and software sold in the EU. This includes everything from connected devices (IoT) to operating systems and even stand-alone software. Very important, this […]
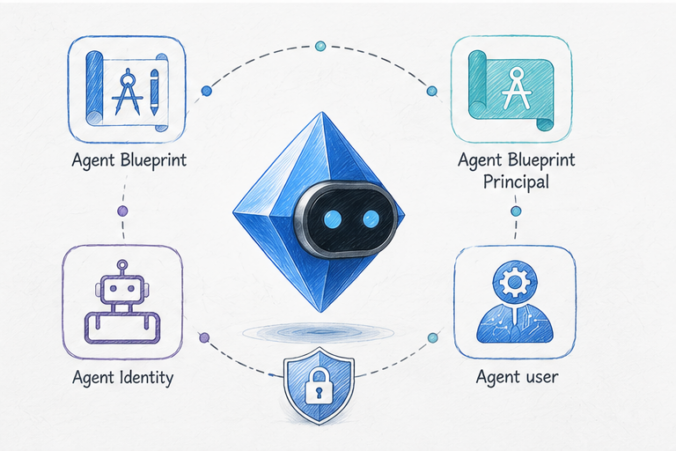
AI agents in your Entra ID tenant? They come with new identities, permissions, and fresh attack paths.
Christian Feuchter breaks down Entra Agent ID security, security-relevant capabilities, control paths, abuse scenarios, and how to review your exposure with EntraFalcon.

SSH is a widely used protocol that provides secure access to remote systems. It enables encrypted communication, file transfers, command execution and shell access for system administration.
Visit https://sshlabs.compass-security.training to learn more about SSH security.

I’m happy to announce that we are releasing the beta version of RAPTR, a fully open source, API driven collaboration platform built specifically for red and purple team engagements.

On paper, the vast majority of crisis plans look reasonable, actionable and complete. Once the rubber hits the road, however, chaos emerges quickly.
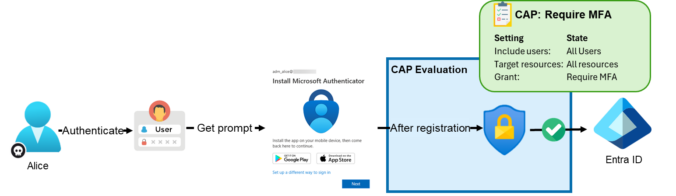
This post is part of a small blog series covering common Entra ID security findings observed during real-world assessments. Each article explores selected findings in more detail to provide a clearer understanding of the underlying risks and practical implications. Conditional Access Policies Conditional Access policies are among the most important security controls in Entra ID. […]
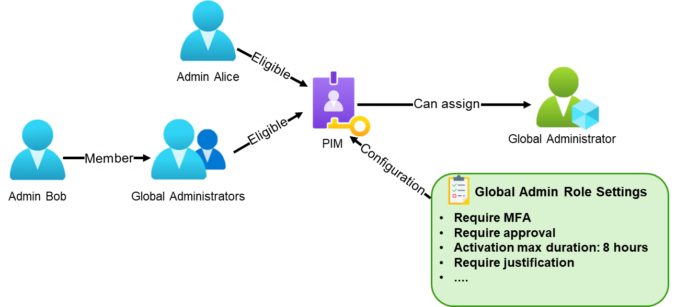
This post is part of a small blog series covering common Entra ID security findings observed during real-world assessments. Each article explores selected findings in more detail to provide a clearer understanding of the underlying risks and practical implications. What Is Privileged Identity Management? Privileged Identity Management (PIM) is a service in Microsoft Entra ID […]
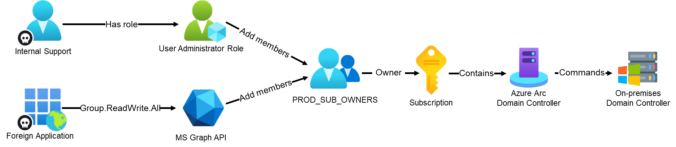
In part 2 of our 4-part series on common Entra ID security findings, we show how seemingly harmless group configurations can be abused to bypass security controls and gain high privileges.
The post shows scenarios where insufficiently protected groups are used to:
weaken Conditional Access protections for administrators
enable privilege escalation through PIM for Groups
grant privileged access to Azure resources, leading to full compromise
We also show how to detect these issues in practice using EntraFalcon and how to mitigate them.
© 2026 Compass Security Blog