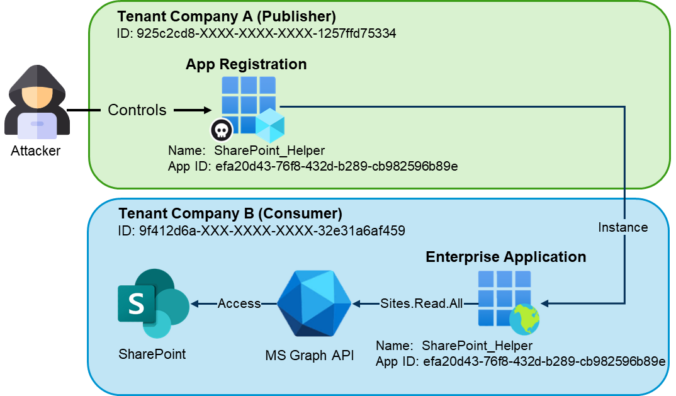
This post is part of a small blog series covering common Entra ID security findings observed during real-world assessments. Each article explores selected findings in more detail to support a clearer understanding of the underlying risks and practical implications. Introduction In the vast majority of tenants we review, there are enterprise applications that originate from […]
Compass Security Blog
Offensive Defense
Page 2 of 30
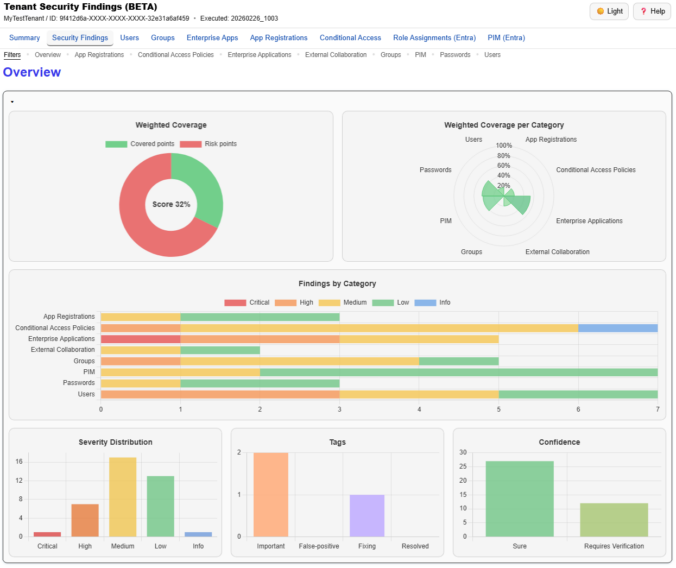
We just released a big update for EntraFalcon. The new Security Findings Report adds an interactive HTML overview to EntraFalcon that consolidates tenant settings and object-based checks into structured security findings. Over 60 checks, graphical charts, filtering, export, and more options are now available.
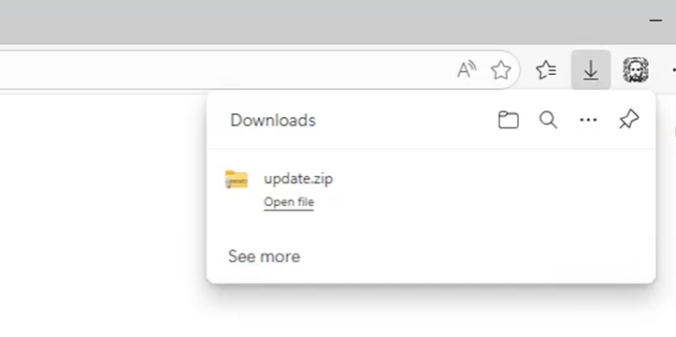
While not new, a self-referencing LNK file in combination with winget configuration instructions can be a viable initial access payload for environments where the Microsoft Store is not disabled.
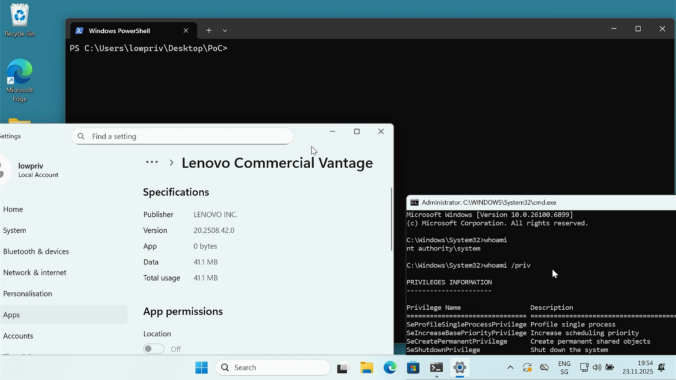
Last year we wrote about a Windows 11 vulnerability that allowed a regular user to gain administrative privileges. Not long after, Manuel Kiesel from Cyllective AG reached out to us after stumbling across a seemingly similar issue while investigating the Lenovo Vantage application. It turns out that the exploit primitive for arbitrary file deletion to gain SYSTEM privileges no longer works on current Windows machines.

Over the course of 2025, we performed several hundred security assessments for our clients. In each of these, security analysts must understand a new environment and often work with unfamiliar technologies. Even for well-known technologies, things change rapidly. Quick learning and adaptability are essential skills.
To keep our security analysts sharp and up to date, we regularly attend security conferences, external courses and trainings but also organize internal sessions. It has become a tradition for us to spend the first week of January learning new things, starting the year improving our know-how.

NTLM is the legacy authentication protocol in Windows environment. In the past few years, I’ve had the opportunity to write on this blog about NTLM Relaying to DCOM (twice), to AD CS (ESC11) and to MSSQL. Today I will look back on relaying to HTTPS and how the tooling improved.
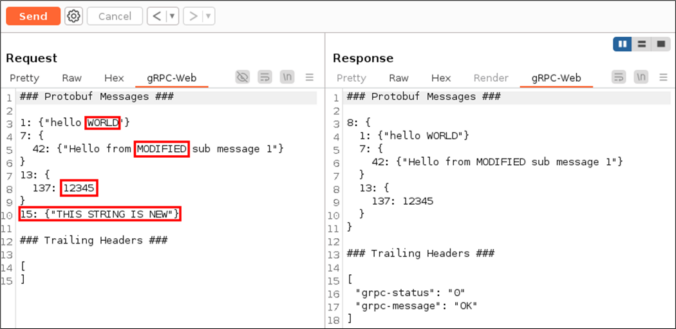
The gRPC framework, and by extension gRPC-Web, is based on a binary data serialization format. This poses a challenge for penetration testers when intercepting browser to server communication with tools such as Burp Suite.
This project was initially started after we unexpectedly encountered gRPC-Web during a penetration test a few years ago. It is important to have adequate tooling available when this technology appears. Today, we are releasing our Burp Suite extension bRPC-Web in the hope that it will prove useful to others during their assessments.

Something a bit wild happened recently: A rival of LockBit decided to hack LockBit. Or, to put this into ransomware-parlance: LockBit got a post-paid pentest. It is unclear if a ransomware negotiation took place between the two, but if it has, it was not successful. The data was leaked.
Now, let’s be honest: the dataset is way too small to make any solid statistical claims. Having said that, let’s make some statistical claims!

The Network and Information Security Directive 2 (NIS2) is the European Union’s latest framework for strengthening cyber security resilience across critical sectors.
If your organization falls within the scope of NIS2, understanding its requirements and ensuring compliance is crucial to avoiding penalties and securing your operations against cyber threats.
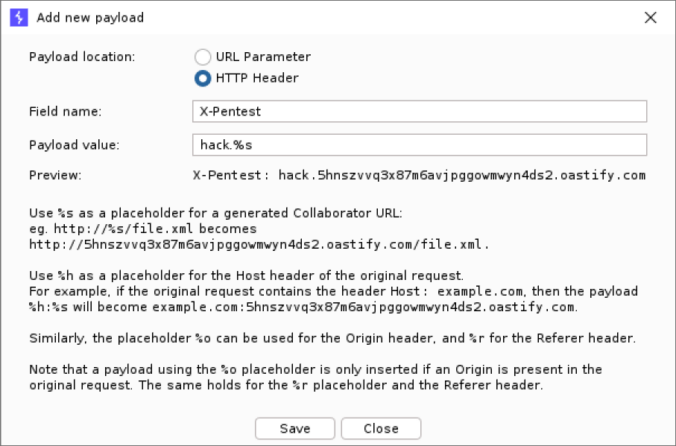
Collaborator Everywhere is a well-known extension for Burp Suite Professional to probe and detect out-of-band pingbacks.
We developed an upgrade to the existing extension with several new exiting features. Payloads can now be edited, interactions are displayed in a separate tab and stored with the project file. This makes it easier to detect and analyze any out-of-band communication that typically occurs with SSRF or Host header vulnerabilities.
© 2026 Compass Security Blog