Companies battle with users who download files from the Internet at work and then execute them. Unsuspicious files are often infected with malware. A common procedure to decrease the amount of infections is to block common bad file types (for example .exe, .scr or .zip), before the files can enter the internal network. The preconditions are that users are only able to communicate with the Internet through a HTTP proxy and the internal email server. A whitelist on the email- and web-content filter, which only allows .docx to go through, can greatly decrease the amount of malware infections. Attackers will have to use exploits (e.g. in the browser, a plugin or office exploits) to perform code execution on the clients.
Sadly, in the case of web content filters, they can all be circumvented. They usually work by looking for HTTP responses whose content types are not safe, for example “application/octet-stream”. Here an example of a typical file download:
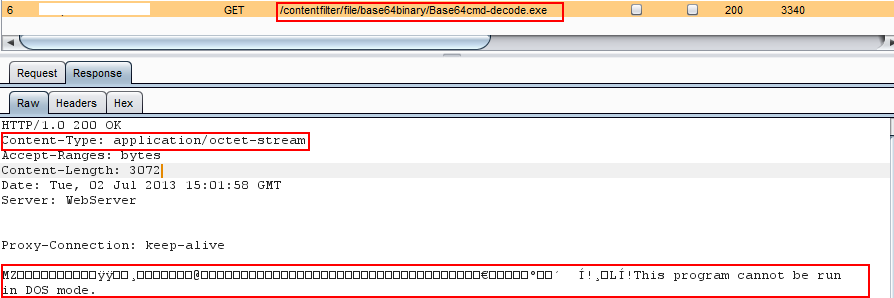
With HTML5, it is possible to create the file to download on-the-fly with JavaScript (by storing the binary as base64 encoded string). As no download request is generated when the download link is clicked, the content-filter can’t deny the download request. It is also possible to misuse Flash for the same purpose.
Example:
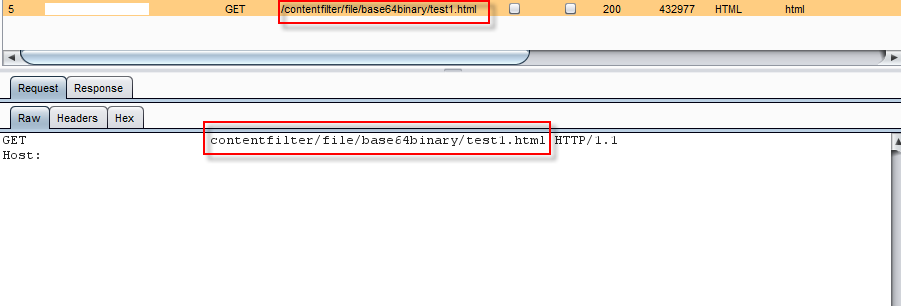
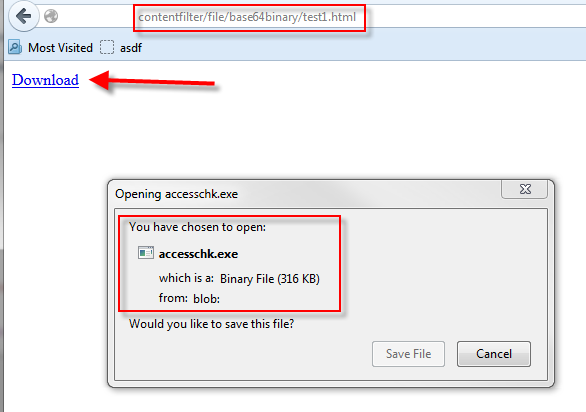 The initial request to retrive the page goes to a plain html file:
The initial request to retrive the page goes to a plain html file:
The response is plain HTML (content type text/html) with javascript:
{kind=link}
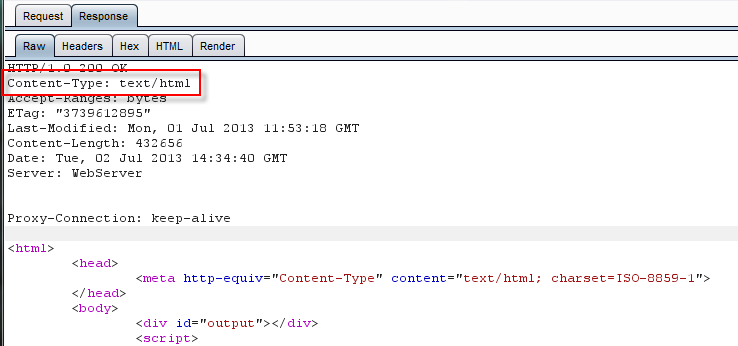
The JavaScript code will extract the base64 encoded binary as a blob and provide a normal download dialog for the user.
There is no simple solution for this problem. Content filters may be able to catch certain pages which use this functionality, but this would break other pages like Google Docs.
The issue was identified at a discussion at the Compass Offsite Meeting 2013 in Berlin. The Proof-of-Concept code (as seen above) has been implemented first by Cyrill Bannwart and works for current versions of Chrome, Firefox and IE10.
Leave a Reply