Modern anti-malware products such as Windows Defender increasingly rely on the use of machine learning algorithms to detect and classify harmful malware. In this two-part series, we are going to investigate the robustness of a static machine learning malware detection model trained with the EMBER dataset. For this purpose we will working with the Jigsaw ransomware.
This blog series is based on my bachelor thesis, which I wrote in summer 2020 at ETH Zurich. In the first part of this blog, we take a look at common evasion tools used by malware writers today.
In the second part, we will investigate the process of the feature engineering of the model and how we can use the gained knowledge to evade a machine learning malware detection model successfully.
Machine Learning Malware Detection Models
In recent years, various machine learning algorithms have been used to further increase the reliability of malware detection. Following the work of the last two decades, different approaches of feature representation, such as the inclusion of n-grams at the byte level, and applied techniques from natural language processing have been studied. In general, current developments in the field of deep learning have significantly improved the usability of machine learning models for object classification, machine translation and speech recognition. Numerous of these approaches use raw images, text, or speech waveforms as input to a machine learning model from which the most useful feature representation for the task at hand is derived. For malware detection, extracting timestamps, code size, imported functions and byte sequences is the right way to create a reliable feature representation. However, regardless of the data set or the feature engineering process, the lifecycle of a machine learning malware detection model usually consists of two phases: the Training phase and the Protection phase. As shown in the picture below, a training set is created with which the model is trained in the Training phase. This process is an art in itself where many things can go wrong. In a paper from 2016 it was found that an unbalanced training set led to serious overfitting. In that work, most of the benign files in the training set were signed by Microsoft, and as a result, the model classified all Microsoft files as benign and all non-Microsoft files as malicious during the Protection phase.
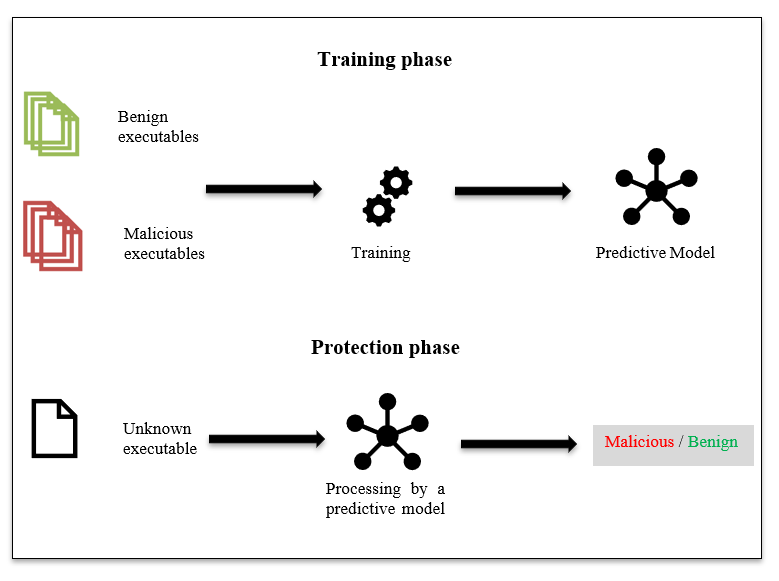
After the Training phase the model is ready for use and can now be used in the Protection phase to classify unknown executables. The output of the trained model is a probability value between 0 and 1, with values closer to 0 for benign behavior and values closer to 1 for malicious behavior. In order to get a definitive result, AV software will round this value up or down. Furthermore, machine learning malware detection is typically used statically or dynamically to classify a particular piece of software. While the dynamic approach extracts the features at runtime, the static approach investigates the features without executing the code. In this blog, we are going to investigate machine learning models using the static approach.
Evasion Theory
After some time of research into the theory of malware evasion, it became apparent that it is possible for an attacker to successfully evade a model if one of the following conditions is met:
• Modeling error: It is almost impossible to create a model that perfectly reflects the real world. Therefore, there are always flaws in the model that could be exploited by an attacker.
• Concept drift: The model is trained with an old training set and no longer up to date. These kind of models are evaded by newer malware.
• Bayes error rate: There exist software or partial software that can be classified as either benign or malicious (for example RAT, which can be interpreted as Remote Administration Tool or as Remote Access Trojaner). So an attacker can take usage of this fact.
This part is for math lovers and can be skipped as it is not necessary for understanding this blog. It contains some formal definitions for the above mentioned conditions:
• Modeling error: Exploiting the fact that the discriminative model approximates the true posterior p(y|x) as p'(y|x), an attacker finds an evasive variant x’ for which
p(y=malicious|x’) > n, but p'(y=malicious|x’) < n for an arbitrary threshold n.• Concept drift: Since the model has been trained to approximate p(y,x), but the distribution benign vs. malicious has drifted to a different distribution p'(y,x).
• Bayes error rate: If p(x|y=benign) and p(x|y=malicious) overlap, there exists the probability for an attacker to find a x’, where p(x’|y=malicious) < p(x’|y=benign).
H. Anderson, A. Kharkar, B. Filar, D. Evans and P. Roth, “Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning,” 2018.
It is obvious that all these conditions, especially Bayes error and modeling error, are strongly dependent on the preprocessing and the data set itself. It would certainly be useful to take a look at the training set and feature engineering of a machine learning malware detection model. I’ll save this for the second part of the blog, where we will dive deeper in the structure of the chosen model.
According to recently published literature, there are mainly three different approaches to attacking a machine learning classifier for malware. The first approach we will refer to as The White-Box Approach. With this approach the structure and the weights of the trained model must be known to the attacker. Given the architecture and the trained weights of the model, the attacker can easily test the model directly to determine how best to increase the model’s loss function using backpropagation (roughly, how best to bypass the model). This is called a gradient-based attack.
In The Black-Box Approach the attacker tries to bypass the detection without any knowledge about model, but has unlimited access to query it. This approach is considered to be the real world scenario, but the chances of success are much lower than with the White-Box approach to evade the model.
The last approach is a combination of the first two approaches. For this reason, this approach receives the appropriate name The Gray-Box Approach. In this approach the attacker knows the structure of the model but not the trained weights. Just like in the Black-Box approach, the attacker can test the model without limitation.
In this blog post we are going to modify the Jigsaw ransomware with commonly used evasion tools to bypass the EMBER Model in the Black-Box approach. In the second part of this blog-series we take a look at the Gray-Box Approach and try to reverse engineer the feature engineering process of EMBER to get necessary information to evade the benchmark EMBER model. But first let’s discuss the rationale behind working with the EMBER project.
Why EMBER?
EMBER is an open dataset for training malware detection machine learning models. This dataset is an open source collection of 1.1 million benign and malicious samples, where their hashes were scanned by VirusTotal. Besides the data set, an out-of-the-box LightGBM-trained decision tree model is provided on their GitHub page. This model achieves a prediction score of 0.9991123 on it’s validation set, which is a very good result considering the size of the data set. In addition, the data set and source code of the pre-processing/feature engineering of the data used to train the model are also available on GitHub. This is exactly what we are looking for: a newly published (2018) all-in-one project with a huge dataset, equipped with a very advanced feature engineering process and a pre-trained, ready-to-use model. After importing this model in our test environment, it is time to find a suitable malware to test it with.
I want to play a game…
Since some malware is quite complex, such as Zeus, it makes sense to limit the search to ransomware. Finally, I think the Jigsaw ransomware is a good choice to work with because it has a simple and straightforward design and because there is a lot of information about it online.
The Jigsaw ransomware is written in C# using the .NET framework. To scare its victims, the Jigsaw ransomware uses the marionette Billy the Puppet from the horror film “Saw” as an image. The ransomware was discovered in April 2016. It was mainly spread via malicious email attachments.
As frightening as the upper image can be to its victims, the malware authors do not seem to be very experienced in writing ransomware. Since the malware is written in .NET and the decryption key is hardcoded in the source code of the ransomware, it is an easy way to recover the encrypted files. Fun fact: When the ransom software first ran in our sandbox environment, the Jigsaw ransomware crashed in the middle of the encryption process. After a long debug session, it turned out that the encryption process could only handle files with a file path of less than 260 characters. So we modify the source code so that the encryption process ignore such files. After this small intervention, this modified version runs smoothly and is ready to query the model.
The Black-Box Approach
In the Black-Box approach, we want to simulate an attacker who has no knowledge about the model but unlimited access to examine the model. Before we start changing our ransomware, it is useful to upload it on VirusTotal to get a rough overview.
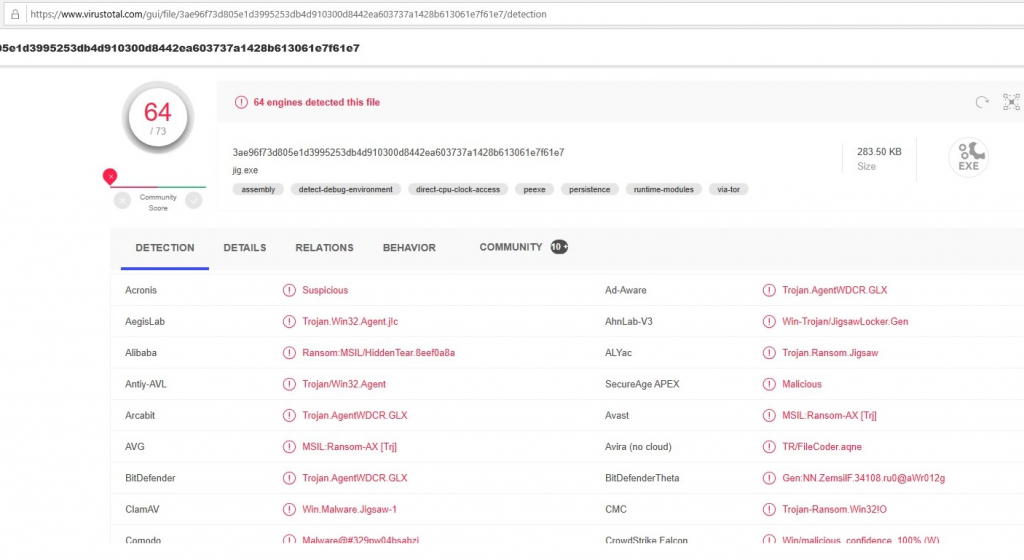
As shown in the picture above, 64 of 73 malware detectors on VirusTotal classify the software as malicious. Not much different is the result of our model:
| Evasion | Score of Model |
| none | 0.999094562 |
Not surprisingly, the ransomware is classified malicious by the model with a score around 0.99. The goal of this blog is to reduce this number to a value below 0.5.
The first thing we want to try is to change some parameters in the compilation process and see what happens. To start with, we add or remove some compiler flags (Add: deterministic, highentropyva+, Remove: optimize+). These flags seem to have the biggest impact on the compilation process. Next, we change the version of the csc compiler (Roslyn version) to version 4.0.30319 and the .NET framework from version 3.5 to 4.5.1. In the result box below, the output of our model is displayed for each attempt
| Evasion | Score of Model |
| Compiler flags | 0.947133742 |
| Framework 4.5.1 | 0.92757697 |
| csc v4.0.30319 | 0.955827899 |
A small reduction of the result is obvious, but since the various compiler commands do not change the file structure significantly, it is not surprising that the results of the model do not differ significantly between our basic version and the slightly modified versions. Let’s continue with more advanced evasion tools.
Obfuscators are tools that convert a program to another version without changing the semantics. Initially, obfuscators were developed to protect the intellectual property of programmers. Malware writers discovered this tool to generate newer versions of their malware, which are harder to be detected by anti-virus software. Examples of these techniques are Dead-Code Insertion, Register Reassignment, and Subroutine Reordering. To obfuscate our ransomware we will work with freeobfuscator. Freeobfuscator operates with an already compiled input file so it is easy to obfuscate our Jigsaw software. The query of our model with the obfuscated ransomware ends in the following result:
| Evasion | Score of Model |
| freeobfuscator | 0.720558865 |
From the result, it is clear that renaming classes and methods with random titles increase the complexity to detect the malicious behavior of the ransomware. However, since the file structure is largely present, the model classifies the obfuscated version with a score of around 0.75. The next evasion tool on our list are packers.
Packers usually use a compression algorithm to make a file smaller. The name comes from the use of packed software that unpacks itself during runtime. Nowadays, packed software usually indicates malicious behavior, as many malware writers use packers to evade AV software. Sometimes packers are used to embed imported DLLs in an executable. One of the most famous packers is called UPX.
Since UPX does not support .NET applications, we are forced to find a similar application that operates on .NET applications. The .netshrink application can compress our ransomware and add unpacking code to the output file so that it remains fully functional, but with reduced size. After compressing our ransomware, the model still detects malicious behavior.
| Evasion | Score of Model |
| netshrink | 0.999518866 |
Using a packer software to compress the file size did not reduce the score of the prediction. On the contrary, the result is even slightly higher than the unchanged Jigsaw ransomware. This raises questions. I think the second part of this blog series will provide answers to this behavior, when the feature engineering process is examined in more detail. In the next test, we compile the Jigsaw source code to a DLL and write a C# code that imports this DLL and calls the main() function of the created DLL. To bind the generated DLL into the executable, we are using the packer Costura.
| Evasion | Score of Model |
| Costura | 0.000083112 |
As shown in the box above, this approach drastically reduces the score of the model. Importing the Jigsaw DLL in a code that only calls the main() function of the imported DLL completely bypasses the model. Now it’s time to upload the Costura-version on VirusTotal.
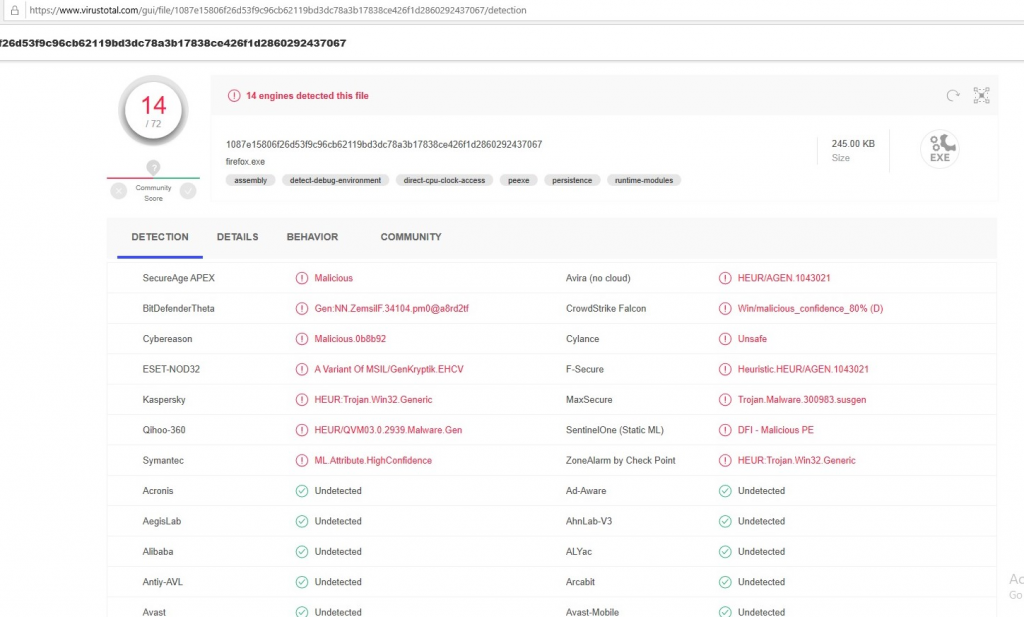
Even the score on VirusTotal has been reduced from 64 to 14, which is a suprising result considering that we have limited ourselves to the static aspect of malware detection in this blog. Since the scanning process from VirusTotal took about 20 min to get this result, it’s very clear that these 14 anti-virus programs detected this ransomware with a dynamic approach when the Jigsaw ransomware wants to change an entry in a registry key.
Conclusion: The Black-Box Approach
Let’s quickly summarize what we have done so far. In this blog, we discussed some background information about machine learning malware detection models and how they can be evaded. We set up a test environment by creating a machine learning malware detection model using the EMBER dataset. To test this model we have thoroughly analyzed the Jigsaw ransomware and tested it in a sandbox environment. Further, two frequently used evasion tools were presented: software obfuscators and runtime packers. Furthermore, we analyzed the results of the model that classifies different modified versions of the Jigsaw ransomware using the presented evasion tools. In the end we were able to successfully bypass the model with the help of the packer Costura. Furthermore, this version was only detected by 14 engines on VirusTotal.
In the second part of this blog series we will take a look at the EMBER dataset, including an insight in the feature engineering process of EMBER. With the gained knowledge we will try detect possible blindspots of the model and use them to evade the ransomware with specially placed modifications.
References
1. H. Anderson and P. Roth, “EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models,” ArXiv eprints, April 2018.
2. E. Raff, Z. Richard, C. Russell, S. Jared, P. Yacci, R. Ward, T. Anna, M. McLean and N. Charles, “An investigation of byte ngram features for malware classification,” Journal of Computer Virology and Hacking Techniques, September 2016.
3. H. Anderson, A. Kharkar, B. Filar, D. Evans and P. Roth, “Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning,” 2018.
4. I. Thomson, “Saw-inspired horror slowly deletes your PC’s files as you scramble to pay the ransom,” The Register, 2016.
5. I. You and K. Yim, “Malware Obfuscation Techniques: A Brief Survey,” in 2010 International Conference on Broadband, Wireless Computing, Communication and Applications, 2010, pp. 297-300.
6. “C# Compiler Options Listed Alphabetically,” Microsoft, [Online]. Available: https://docs.microsoft.com/enus/dotnet/csharp/language-reference/compiler-options/listed-alphabetically. [Accessed 14 5 2020].
7. “freeobfuscator,” Free Obfuscator, 2018. [Online]. Available: https://freeobfuscator.com/. [Accessed 14 5 2020].
8. F. Guo, P. Ferrie and T.-c. Chiueh, “A Study of the Packer Problem and Its Solutions,” in Recent Advances in Intrusion Detection”, Berlin, Springer Berlin Heidelberg, 2008, pp. 98-115.
9. L. Molnár, M. F. Oberhumer and J. F. Reiser, “UPX,” The UPX Team, 1996-2020. [Online]. Available: https://upx.github.io/. [Accessed 15 5 2020].
10. “.netshrink,” PELock LLC, 2001 – 2020. [Online]. Available: https://www.pelock.com/products/netshrink. [Accessed 15 5 2020].
11. “Costura,” Fody, [Online]. Available: https://github.com/Fody/Costura. [Accessed 15 5 2020].
Leave a Reply