“This application is hosted in our internal network and not exposed to the Internet, why should we invest money and time in securing it? Our employees have access to that data anyway…”
If you performed penetration tests for a while you may have probably already encountered this argument before. But which attack can really show the threat potential of an unsecured internal application? During a search for this answer, I stumbled upon a really old vulnerability that still remains relevant today: DNS rebinding.
If you are already familiar with web application security you can probably skip some of the following sections meant to share some basic knowledge to better understand the vulnerability.
Browsers are the way in!
Hackers on the Internet can use the front door to run code on people’s computers without having to convince you to open that strange file you just downloaded. As soon as you open your favorite browser and start surfing the web a lot of different pieces of code created by various companies and individuals will be executed in a somewhat controlled environment.
Of course, browsers will use any possible means to prevent malicious code lying around on the Internet to harm their users. However, there are still gaps in the trade-off between functionality and security where features are misused to perform malicious actions on the victim’s computer.
Same-Origin Policy
One of the browser’s defense methods is the so-called ‘Same-Origin Policy’ (or SOP for the acronym lovers out there), which restricts how websites loaded from one origin can interact with resources from other origins. What is this ‘origin’ I was referring to you ask? For browsers, the origin of a website is a combination of the protocol used to connect to it (e.g.: http://), the website’s Fully Qualified Domain Name (FQDN) (e.g.: www.example.com) and the port used for the connection (e.g.: 80).
For example, the following URLs all have the same origin:
- http://www.example.com/index.html
- http://www.example.com/another/path.txt
- http://www.example.com:80/same/http/port.php
- http://user:[email protected]/login.html
On the other hand, these URLs do not have the same origin of http://www.example.com/index.html:
- https://www.example.com/index.html (different protocol)
- http://www.example.com:8080/index.html (different port)
- http://xxx.example.com/index.html (different FQDN)
Browsers that follow the same-origin policy will restrict cross-origin interactions. JavaScript code originated from http://attacker.com/infected.html that sends an HTTP requests to http://www.example.com/secret.html will be prevented from reading the content of the responses.
Cross-Site Request Forgery
What if the attacker’s JavaScript code doesn’t care about the response but just wants to trigger an action on the server? That’s when Cross-Site Request Forgery (CSRF) attacks come into play.
In this case preventing resources from reading cross-origin responses is not enough, the browser needs to block the request before it gets sent. Even in this case most browsers will enforce the same-origin policy by imposing certain limitations on cross-origin requests. If the criteria of being “simple HTTP requests” are not satisfied browsers will ask the receiving server (using a pre-flight request) for permission before sending the request, but if the criteria are satisfied the protection against CSRF attacks is left to website developers.
DNS Rebinding
So, what does all of this have to do with DNS rebinding and unsecured internal applications? Well, CSRF attacks work well against internal as well as external websites, but because of its limitations it’s not always useful. A sensitive data leak becomes a scary scenario for big enterprises, and here’s where DNS rebinding may play an important role.
An old attack
As I said before, the idea behind DNS rebinding is old. It was already around in the nineties. We can find a description by Princeton University dating back to 1996 that shows how it is possible to establish communication between a server on the Internet and a web application in an internal network through the victim’s browser.
It just works
Summarized, DNS rebinding works by leading a victim to a website containing the attacker’s code, which will exploit short-lived DNS entries to switch the IP resolved for the attacker’s URL from the real external to an internal one. This will trick the browser into sending HTTP requests to internal hosts and then delivering the responses back into the attacker’s hands.
For example, let’s take a victim company Victim Inc. that hosts their internal web server behind a firewall so that it can be reached only by traffic coming from other internal hosts. Employees can access the hosted web application on the web server with IP 10.0.0.10 when they are connected to the internal network.
The attacker controls the website http://attacker.com and the DNS server for the corresponding domain. For various possible reasons (e.g.: cat videos) an employee of Victim Inc. is browsing http://attacker.com on his corporate computer in the internal network.
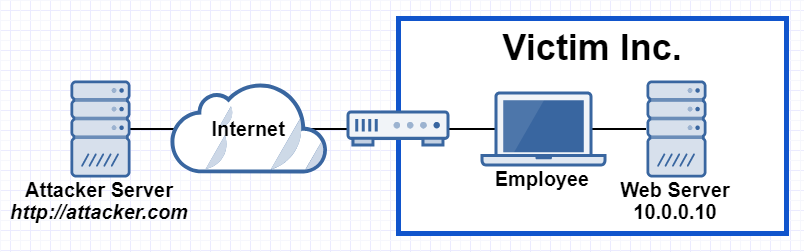
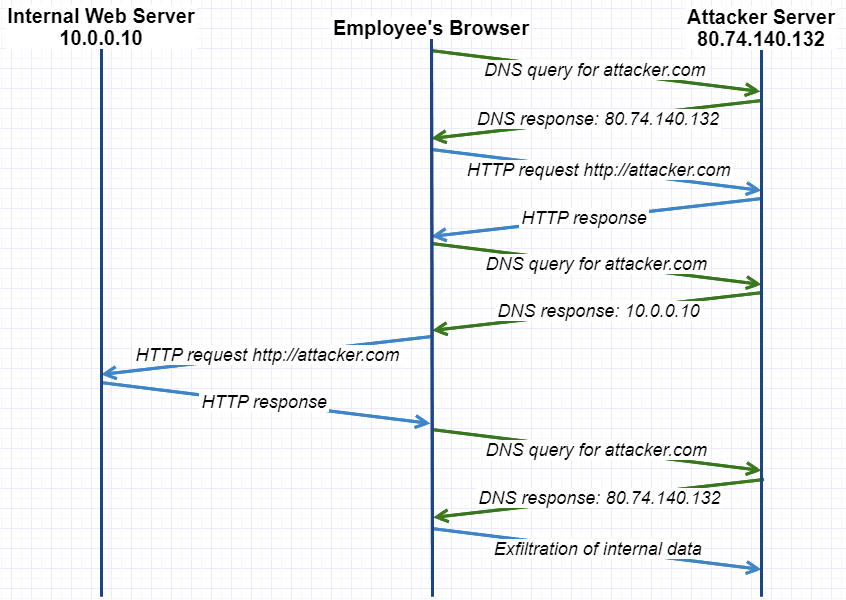
When the browser wants to connect to attacker.com it has to resolve its domain name first and send a DNS query. The authoritative DNS server for attacker.com is controlled by the attacker and responds with the correct IP 80.74.140.132, but gives it a very short Time-To-Live (TTL). The browser establishes the connection and loads the website’s content.
The newly loaded website’s content (e.g.: JavaScript) will attempt to perform another request for http://attacker.com and since the first DNS entry is already stale because of the short TTL, the server will try to resolve the domain name again. This second time the attacker’s DNS server answers with an internal IP 10.0.0.10 to the query.
What happens on the browser now? Well, the DNS entry is updated and attacker.com now points to the IP 10.0.0.10, and since there is no difference in protocol, host name or port the request satisfies the same-origin policy. The request is thus sent to the internal web server and the browser will hand over the response to the attacker’s code, which can now exfiltrate the information to the attacker’s own infrastructure.
Mitigations
The most effective way of mitigating DNS rebinding attacks is to protect the internal web application directly by:
- using TLS: the certificate’s Common Name of the internal application will not match the attacker’s hostname
- enforcing user authentication: no login = no access (remember to change those default credentials!)
- validation of host header in HTTP requests: host header will contain the attacker’s hostname
Since the attack has been known for decades, one might wonder why browsers have not already implemented mitigations against it. However, the mechanisms used by DNS rebinding attacks are also employed by commercial applications since DNS entries with short TTL are of great importance for proper load balancing of traffic-intensive websites.
It is also possible to block DNS rebinding on a firewall by dropping any response coming from the Internet resolving domain names to internal IPs. This approach comes with all the issues of backlisting, from misconfiguration to not covering all possible cases. For example, the IP address 0.0.0.0 resolves to localhost on Linux and MacOS and might be left out from the blacklist or the DNS response could contain a CNAME entry for an internal hostname that gets translated into its IP address by the internal nameserver, bypassing simple IP filters.
Taking it to the next level
Ok, the basics and mitigations are taken care of, but now it’s time to take this attack to the next level, and there is currently no better way than by using Gérald Doussot and Roger Meyer’s framework Singularity of Origin presented at DEF CON 27 in 2019.
One of the main misconceptions about DNS rebinding that Gérald and Roger debunk, is that this kind of attack takes too long to execute, since most modern browsers set a lower bound to DNS TTL of around 60 seconds. This means that the simple attack scenario explained before would take more than 2 minutes to execute. However, by using cache-flooding techniques and multiple answers in DNS responses it is possible to perform successful rebinding in ~4 seconds for targets bound to the loopback interface (e.g.: 127.0.0.1) and 5-40 seconds for the rest.
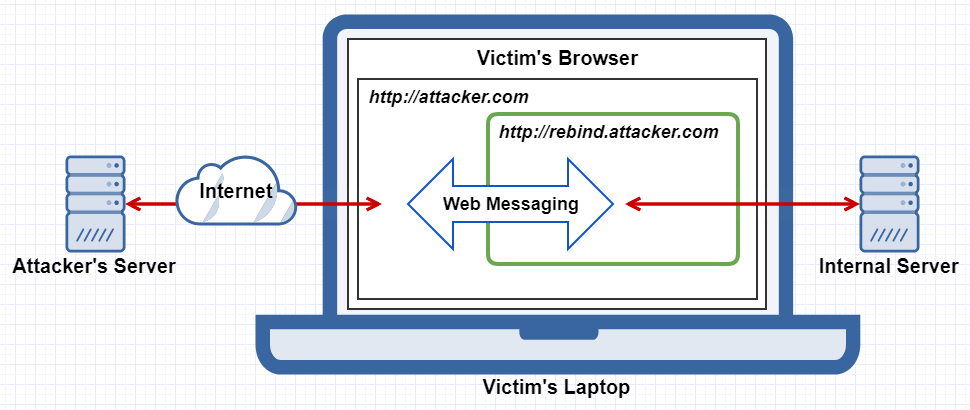
With multiple iframes and HTML5’s web messaging feature it’s also possible to create a stable communication channel between the attacker’s server and the internal target, once DNS rebinding is successful, removing the need to keep rebinding the IP back and forth. This also allows for Singularity’s “Hook and Control” attack, which gives the attacker a full browsing experience on a targeted internal web application.
Conclusions
Unsecured internal web applications have never been a good idea and this old attack demonstrates how browsers can be used to proxy HTTP traffic between internal and external hosts. With Gérald Doussot and Roger Meyer’s framework anyone can generate a good proof-of-concept that shows the high risks of leaving sensitive applications unprotected behind a firewall.
With the rise in Internet of Things (IoT) devices deployed all around the globe, it is imperative that basic security measures get implemented on any sensitive interface, even if it’s not directly exposed to the Internet.
Leave a Reply